
A.I. chip design, and it’s critical that we keep it that means." By then, although, DeepSeek had already released its V3 giant language mannequin, and was on the verge of releasing its extra specialised R1 mannequin. Professional Plan: Includes extra features like API entry, precedence help, and extra superior fashions. Through inside evaluations, DeepSeek-V2.5 has demonstrated enhanced win charges against models like GPT-4o mini and ChatGPT-4o-latest in duties equivalent to content creation and Q&A, thereby enriching the general user experience. DeepSeek 2.5: How does it compare to Claude 3.5 Sonnet and GPT-4o? Additionally it is believed that DeepSeek outperformed ChatGPT and Claude AI in several logical reasoning assessments. Its a open-source LLM for conversational AI, coding, and downside-fixing that not too long ago outperformed OpenAI’s flagship reasoning model. We evaluate our mannequin on LiveCodeBench (0901-0401), a benchmark designed for dwell coding challenges. The platform is designed for companies, builders, and researchers who want reliable, high-performance AI models for a wide range of duties, including text technology, coding help, real-time search, and advanced downside-solving.
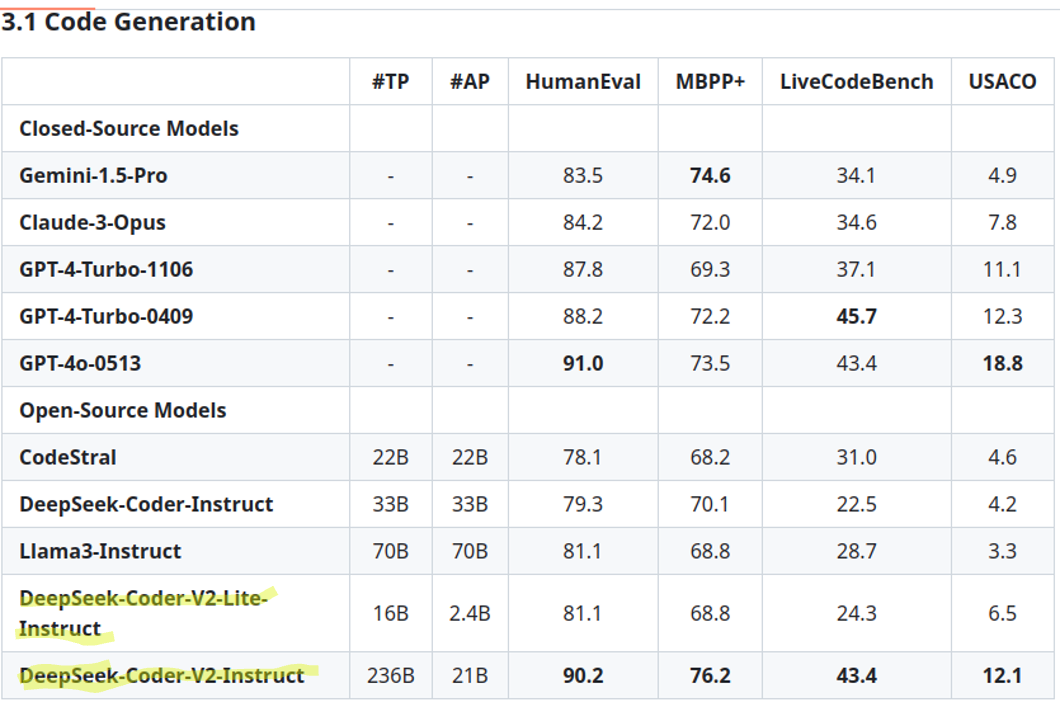 This performance highlights the model’s effectiveness in tackling live coding tasks. This function is especially helpful for tasks like market research, content creation, and customer support, the place access to the most recent information is important. Which means that users can ask the AI questions, and it will present up-to-date info from the web, making it a useful instrument for researchers and content material creators. Your AMD GPU will handle the processing, providing accelerated inference and improved performance. We first introduce the fundamental structure of DeepSeek-V3, featured by Multi-head Latent Attention (MLA) (DeepSeek-AI, 2024c) for environment friendly inference and DeepSeekMoE (Dai et al., 2024) for economical coaching. For consideration, we design MLA (Multi-head Latent Attention), which utilizes low-rank key-value union compression to eradicate the bottleneck of inference-time key-worth cache, thus supporting environment friendly inference. SGLang at present helps MLA optimizations, FP8 (W8A8), FP8 KV Cache, and Torch Compile, offering the very best latency and throughput among open-supply frameworks. The most effective model will range but you'll be able to take a look at the Hugging Face Big Code Models leaderboard for some steerage. 2E8B57 Think about what shade is your most preferred color, the most effective one, your favorite coloration.
This performance highlights the model’s effectiveness in tackling live coding tasks. This function is especially helpful for tasks like market research, content creation, and customer support, the place access to the most recent information is important. Which means that users can ask the AI questions, and it will present up-to-date info from the web, making it a useful instrument for researchers and content material creators. Your AMD GPU will handle the processing, providing accelerated inference and improved performance. We first introduce the fundamental structure of DeepSeek-V3, featured by Multi-head Latent Attention (MLA) (DeepSeek-AI, 2024c) for environment friendly inference and DeepSeekMoE (Dai et al., 2024) for economical coaching. For consideration, we design MLA (Multi-head Latent Attention), which utilizes low-rank key-value union compression to eradicate the bottleneck of inference-time key-worth cache, thus supporting environment friendly inference. SGLang at present helps MLA optimizations, FP8 (W8A8), FP8 KV Cache, and Torch Compile, offering the very best latency and throughput among open-supply frameworks. The most effective model will range but you'll be able to take a look at the Hugging Face Big Code Models leaderboard for some steerage. 2E8B57 Think about what shade is your most preferred color, the most effective one, your favorite coloration.
Sign up for over hundreds of thousands of free tokens. This gives full management over the AI models and ensures complete privateness. Individuals who want full management over knowledge, security, and performance run regionally. For users who prioritize data privacy or need to run AI models on their very own machines, this AI platform offers the choice to run fashions domestically. Ollama Integration: To run its R1 models regionally, users can set up Ollama, a tool that facilitates running AI models on Windows, macOS, and Linux machines. After logging in, you can start utilizing AI’s fashions, discover your settings, and regulate your preferences. This coaching was completed using Supervised Fine-Tuning (SFT) and Reinforcement Learning. This complete pretraining was adopted by a means of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to totally unleash the model’s capabilities. Go to the official site homepage and begin the registration process. Free Plan: Offers core options reminiscent of chat-based mostly fashions and primary search functionality. Here’s how its responses in comparison with the Free DeepSeek variations of ChatGPT and Google’s Gemini chatbot. Compared with DeepSeek 67B, DeepSeek-V2 achieves stronger performance, and in the meantime saves 42.5% of coaching costs, reduces the KV cache by 93.3%, and boosts the maximum generation throughput to greater than 5 instances.
This has made more spiritual practices go underground in a extra non-public setting"-like, for instance, a computer or cellphone display screen. It was China and the non-Western world that saved the Western-designed pc - saved it, that's, from its foundational limitations, both conceptual and materials. The world of synthetic intelligence (AI) is evolving quickly, and new platforms are emerging to cater to different ne a powerful and value-effective solution for builders, researchers, and businesses trying to harness the ability of large language models (LLMs) for quite a lot of tasks. Its an revolutionary AI platform developed by a Chinese startup that specializes in chopping-edge synthetic intelligence fashions. He questioned the financials DeepSeek is citing, and questioned if the startup was being subsidised or whether its numbers were appropriate. That each one being said, LLMs are nonetheless struggling to monetize (relative to their cost of both coaching and operating). It includes 236B complete parameters, of which 21B are activated for every token. Note: The full size of DeepSeek-V3 fashions on HuggingFace is 685B, which incorporates 671B of the main Model weights and 14B of the Multi-Token Prediction (MTP) Module weights. Conversely, if the guidelines indicate that the mix of distillation and the other refining techniques used for R1 are so subtle that they created a new mannequin in its own right, then the provisions of the AI Act for GPAI models will apply to it starting August 2, 2025. To be extra precise, the AI Act states that GPAI models already placed in the marketplace before that date should "take the necessary steps so as to adjust to the obligations by 2 August 2027," or in two years.
Should you loved this short article and you would like to receive more information about Deepseek Online chat please visit our own site.
댓글 달기 WYSIWYG 사용